Pourquoi IRON : genèse d'un indice de robustesse numérique
Les termes techniques et acronymes utilisés dans cet article sont définis dans le glossaire.
Le dernier article de cette série se terminait par une question : comment structurer l’évaluation de la robustesse d’une organisation face à des crises qui se chevauchent, dont les horizons de rétablissement dépassent l’intervalle entre les chocs, et face auxquelles le PRA et le PCA atteignent leurs limites ? Cet article y répond.
Mais la question n’est pas née de la crise d’Ormuz. Elle était posée, sous une autre forme, dans le livre blanc Voyage vers la robustesse publié en janvier 2026 [1] : que se passerait-il si l’un de vos services numériques devenait indisponible ? La série sur la chaîne numérique y arrive par la géopolitique, le climat et la polycrise. Le livre blanc y arrivait par la dépendance organisationnelle. Quel que soit le chemin, une question reste sans réponse dans les référentiels actuels : la substituabilité des services numériques sur un horizon long, évaluée processus par processus.
Le livre blanc et ses limites assumées
Le livre blanc Voyage vers la robustesse [1], que j’ai rédigé pour Infogreen Factory avec le soutien de l’ADEME, du CNRS et de l’INRIA, posait des fondations que je considère solides. La plus structurante est la distinction entre résilience et robustesse. La résilience est la capacité d’un système technique à encaisser un choc et à revenir à son état antérieur. La robustesse, telle que nous inspire le biologiste Olivier Hamant [2], va au-delà : c’est la capacité d’une organisation à maintenir ses fonctions même si le système technique ne revient pas — une question organisationnelle, pas seulement technique.
Le livre blanc proposait aussi une matrice de criticité croisant deux dimensions — la criticité d’un processus métier et la substituabilité de son service numérique — sur une grille qualitative 3×3, et une spirale d’amélioration en quatre tours (sécuriser, optimiser, expérimenter, approfondir).
Le livre blanc pouvait traiter trois dimensions. Contraint par le temps et le volume, il n’en a formalisé que deux. L’axe résilience — la capacité technique du service à résister aux pannes — a été volontairement écarté : les organisations connaissent la résilience, elles investissent dedans depuis des années, les référentiels la couvrent (ISO 27001, DORA). La substituabilité, en revanche, est un territoire beaucoup moins balisé. Dès novembre 2025, j’identifiais qu’il faudrait aller plus loin. La matrice posait la bonne question mais restait incomplète — deux axes sur trois — et trop subjective : deux évaluateurs pouvaient arriver à des scores différents sur le même processus.
J'ai créé IRON pour prolonger le livre blanc sur ces deux axes. La matrice de criticité passe d’une grille qualitative 3×3 sur deux dimensions à une grille quantitative 5×5 sur trois dimensions. L’axe résilience, qui manquait, rejoint la criticité et la substituabilité. La spirale se projette sur les zones de priorité.
Ce que les outils existants couvrent, et où ils s’arrêtent
L’échelle d’intensité situationnelle que je propose ici gradue les crises non par leur cause mais par leurs effets sur l’organisation — à la manière de l’échelle de Mercalli pour les séismes. Ce n’est pas un outil de mesure mais un cadre de positionnement, susceptible d’être revu et adapté.
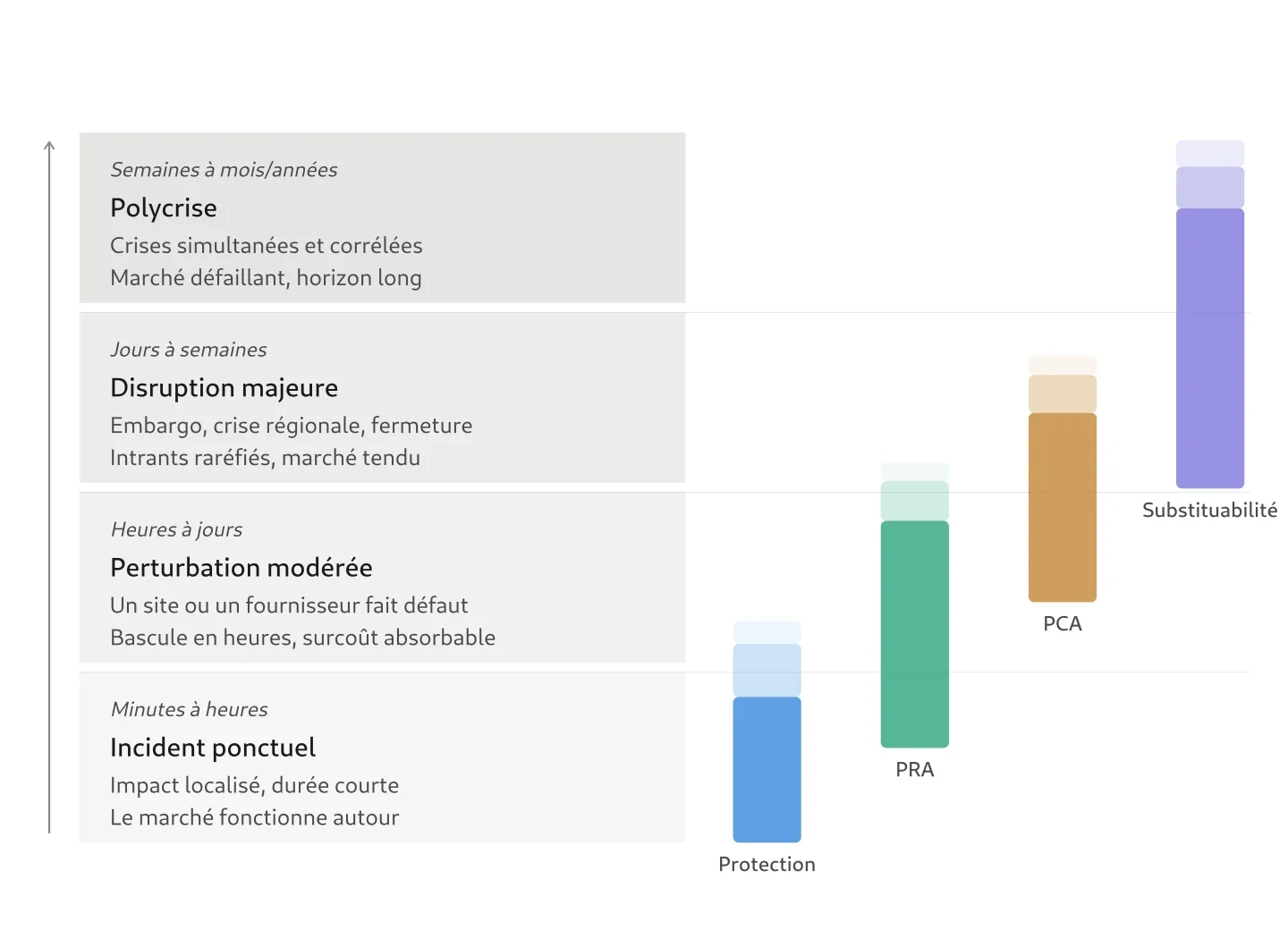
Les barres indiquent le type de choc que chaque outil traite en premier recours, pas le niveau situationnel qu’il « couvre ». La protection continue d’absorber les incidents ponctuels à chaque niveau, y compris en polycrise. Ce que le dégradé montre, c’est qu’à mesure que la gravité situationnelle monte, l’outil ne suffit plus à répondre à la situation d’ensemble et le relais passe à l’outil suivant.
En bas de l’échelle, les deux premiers niveaux sont connus. L’incident ponctuel (un serveur tombe) se résout en minutes à heures par la protection et la redondance. La perturbation modérée (un datacenter indisponible) dure de quelques heures à quelques jours et relève du PRA : bascule, rétablissement planifié, marché fonctionnel autour.
Au-delà de ces deux niveaux, la nature du problème change. Une disruption majeure — Ormuz, un embargo, une catastrophe régionale — s’inscrit dans un horizon de jours à semaines. Le PCA prend le relais pour les scénarios dont la fin reste planifiable. Les PCA les plus matures intègrent déjà une forme de substituabilité — un mode dégradé documenté, un processus manuel pour les fonctions critiques. Ce travail n’est pas à refaire. Mais le PCA couvre la substituabilité sur un horizon court et pour les processus identifiés dans le BIA, pas pour l’ensemble de l’organisation. Au niveau 4 — la polycrise, des crises simultanées et corrélées — l’horizon se compte en semaines, en mois, parfois en années. Le marché ne fonctionne plus normalement, les intrants ne sont plus disponibles. Seule une substituabilité formalisée, testée, et dimensionnée pour la durée répond à ce niveau.
La série d’articles sur la chaîne numérique a montré, données à l’appui, que la situation actuelle se situe de plus en plus haut sur cette échelle. Six crises majeures en six ans (COVID, pénurie de semi-conducteurs, guerre en Ukraine, sécheresse du canal de Panama, attaques houthistes, crise d’Ormuz), aucune résolue quand la suivante a frappé. Des horizons de rétablissement de trois à cinq ans (Ras Laffan), de six ans (barrage du canal de Panama). El Niño attendu cet été sur une chaîne qui n’a pas fini d’absorber Ormuz. Les organisations sont préparées pour les niveaux 1 et 2, raisonnablement outillées pour le bas du niveau 3.
Le McKinsey Global Institute estimait en 2020 qu’une disruption d’un mois se produisait tous les 3,7 ans [3]. Depuis 2020, l’intervalle réel est inférieur à un an.
La protection et la résilience ne cessent pas de fonctionner quand la situation s’aggrave. Un serveur tombe pendant une polycrise exactement comme il tombe un mardi ordinaire, et la redondance l’absorbe de la même façon. Ce que l’échelle montre, c’est que la protection traite les incidents ponctuels qui surviennent à chaque niveau — mais qu’elle ne suffit pas à répondre au niveau situationnel lui-même quand celui-ci monte. Elle reste pourtant indispensable aux niveaux supérieurs : sans elle, chaque incident déclencherait la substituabilité — ce qui signifie mobiliser des ressources mutualisées, passer en processus manuels, activer des circuits qui s’usent si on les sollicite trop souvent. La substituabilité doit rester un mode rarement déclenché ; c’est le rôle de la résilience que d’absorber les chocs courants pour éviter de la solliciter à tort. Quand la situation dépasse ce que la résilience peut absorber, la substituabilité est le seul filet qui reste — et elle doit tenir des mois, pas des heures.
C’est ce qu’a montré le cas d’une municipalité suédoise frappée par un ransomware en 2025 : la résilience technique avait été dépassée, et ce sont les employés non techniques qui ont maintenu les services publics avec des processus analogiques [4].
Le métier d’abord
Renforcer le SI, relocaliser les données, diversifier les fournisseurs cloud : ces actions améliorent la résilience, ce qui couvre les niveaux 1 et 2 de l’échelle. Aux niveaux 3 et 4, la question change de nature : elle ne porte plus sur le service numérique mais sur le processus métier qu’il soutient. Le livre blanc le formulait déjà : la robustesse ne se mesure pas au nombre de serveurs de secours, mais à la capacité de l’organisation à maintenir ses fonctions vitales sans eux [1]. IRON part de là : le point d’entrée de l’évaluation est le processus métier, pas le service numérique.
Prenons un système de gestion d’entrepôt dont les serveurs dépendent de puces TSMC et de mémoire Samsung — les deux nœuds de convergence identifiés dans l’article sur la polycrise. L’approche classique demande : comment protéger ce système ? Redondance, site de repli, contrat de maintenance prioritaire. L’approche par le métier demande : comment l’entrepôt fonctionne-t-il sans ce système pendant trois mois ? Si la réponse est « avec des bordereaux papier et deux personnes supplémentaires », c’est un mode dégradé identifié et chiffrable. Si la réponse est « il ne fonctionne pas » — et c’est un cas fréquent pour les processus à forte criticité — l’effort d’investissement doit s’y concentrer.
Les quatre articles sur la chaîne de fabrication ont montré que le substrat matériel du numérique est fragile, concentré, corrélé et soumis à des crises qui se chevauchent. Quand le système de gestion d’entrepôt est substituable par des bordereaux papier, la redondance technique et le stock de matériel servent de pont le temps de basculer. Quand le processus n’a pas d’alternative, la situation est plus exposée : la redondance accrue et le stock sont la seule protection, et il faut pouvoir tenir le temps que la crise passe ou qu’une solution de substitution soit trouvée. Le livre blanc identifiait déjà cette contrainte [1]. C’est cette distinction, processus par processus, qu’IRON formalise.
IRON : trois axes, une mesure
IRON est la conjonction d’un modèle d’évaluation et d’une démarche opérationnelle [5]. Le modèle part du processus métier. Pour chaque couple processus / service numérique, il évalue trois grandeurs. La première est la criticité du processus : quel serait l’impact d’une indisponibilité, sur les plans opérationnel, réglementaire et réputationnel ? C’est le point d’entrée de l’évaluation. La deuxième est la substituabilité du service : existe-t-il une alternative qui ne partage pas les mêmes dépendances que le service principal — qu’elle soit numérique, low-tech ou manuelle — et a-t-elle été testée ? La troisième est la résilience du service : sa capacité à résister aux pannes, évaluée à travers quatre familles (redondance, diversification, protection, rapidité de rétablissement).
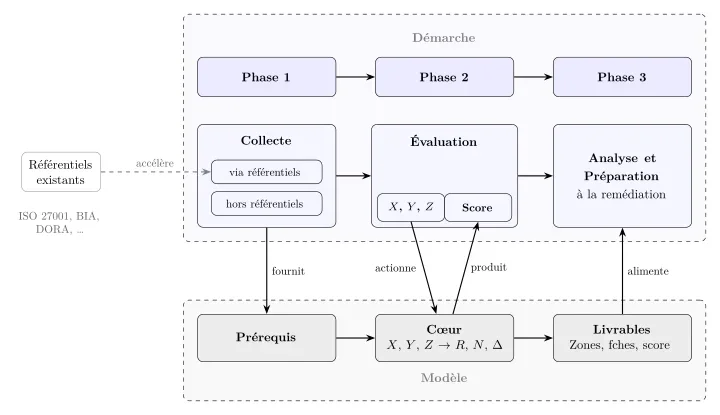
Le croisement de la substituabilité et de la résilience produit un taux de maîtrise. Le choix d’un produit plutôt que d’une somme amplifie le poids de chaque axe : une résilience excellente ne compense pas l’absence de substituabilité. L’écart entre la criticité du processus et ce taux de maîtrise détermine la zone : rouge si la criticité dépasse largement la maîtrise, orange si l’équilibre est fragile, vert si la maîtrise dépasse la criticité. Ce sont les mêmes zones que la matrice du livre blanc — et c’est voulu. La spirale du livre blanc (sécuriser, optimiser, expérimenter) correspond aux tours de traitement IRON (rouge d’abord, orange ensuite, vert enfin) ; IRON y ajoute la capacité de transformer les zones en actions hiérarchisées.
Concrètement, là où la matrice disait « ce processus est en zone rouge, traitez-le en priorité », IRON permet d’identifier le levier : c’est la diversification du service qui est insuffisante, ou c’est le mode dégradé qui n’a jamais été testé, ou les deux. Et quand un même service numérique est partagé par plusieurs processus, améliorer sa résilience fait progresser tous les couples concernés ; c’est le levier le plus rentable, qu’IRON rend visible.
IRON ne remplace pas les référentiels existants ; il les consomme. ISO 27001 fournit les données de résilience, le BIA de l’ISO 22301 fournit la criticité. IRON croise ces résultats dans une mesure unique de robustesse et priorise les actions selon la criticité réelle de chaque processus. Plus les référentiels sont en place, plus la collecte est rapide ; et c’est leur croisement qui donne à l’ensemble une portée qu’aucun d’eux n’a séparément.
La suite
Ce parcours n’est pas achevé. L’échelle d’intensité situationnelle présentée dans cet article est un premier cadre de positionnement, pas un résultat définitif, et les retours des praticiens affineront le modèle.
Je prépare une version 2 du livre blanc dans laquelle IRON remplacera la matrice de criticité. Le cadre s’y prête : la spirale reste le parcours, les zones de priorité restent le résultat, et les axes fournissent la granularité nécessaire pour prioriser les actions plus finement. Les organisations qui ont investi dans un PRA, un PCA, une certification ISO ne repartent pas de zéro — elles construisent sur leurs acquis en y ajoutant la dimension que la polycrise a rendue urgente. Le guide IRON et la documentation associée détaillent la démarche pour commencer cette évaluation.
Références
- Infogreen Factory. Voyage vers la robustesse — livre blanc. Janvier 2026. https://infogreenfactory.green/publications/livre-blanc-robustesse/
- Hamant O. Antidote au culte de la performance : la robustesse du vivant. Gallimard, collection Tracts n° 50. 2023.
- McKinsey Global Institute. Risk, resilience, and rebalancing in global value chains. Août 2020. https://www.mckinsey.com/capabilities/operations/our-insights/risk-resilience-and-rebalancing-in-global-value-chains
- Holmström A. et Große C. Not All Heroes Wear Capes: Cyber Resilience of the Social Administration at a Swedish Municipality. Risk, Hazards & Crisis in Public Policy, 16(3). 2025. https://doi.org/10.1002/rhc3.70024
- Peccini S. IRON — Guide complet : modèle et démarche d’évaluation. https://conseil.peccini.fr/documents/iron/IRON-guide.pdf
Licence
Ce document est mis à disposition selon les termes de la licence Creative Commons Attribution – Pas d’Utilisation Commerciale – Pas de Modification 4.0 International (CC BY-NC-ND 4.0). © Stéphan Peccini, 2026